MIT6.824分布式课程
Zookeeper
对于写, 都是线性一致的 对于读, 每个客户端保自己证看到的是线型一致的
- linearizability Write
- FIFO client order说的就是这个
正常的流程 zookeeper有几个缺点
zookeeper有几个缺点
- 只能保证自己能读到自己放的最新的数据, 自己放, 别人读就不保证能读到最新的了
- 解决办法就是, 发一个sink, 应该就是空的写操作, 这样就保证读到最新的, 但这样感觉不如全从leader走, 一般都不用这个, 这也是zookeeper的缺点
- 因为zookeeper一般用于存放配置文件, 所以有一个node概念, 更新这个node就像更新数据库的一条信息, 多个node应该是构成一个文件, 所以就需要有数据库的特性, 事务, 需要原子更新.
- 所以是这样做的, 多个znode准备好后, 会生成一个ready file, 表示已经更新完了, 可以读了, 如果没有ready file就不能读, 没准备好
- 有可能读到bad Data
- 像这样就是错误的数据
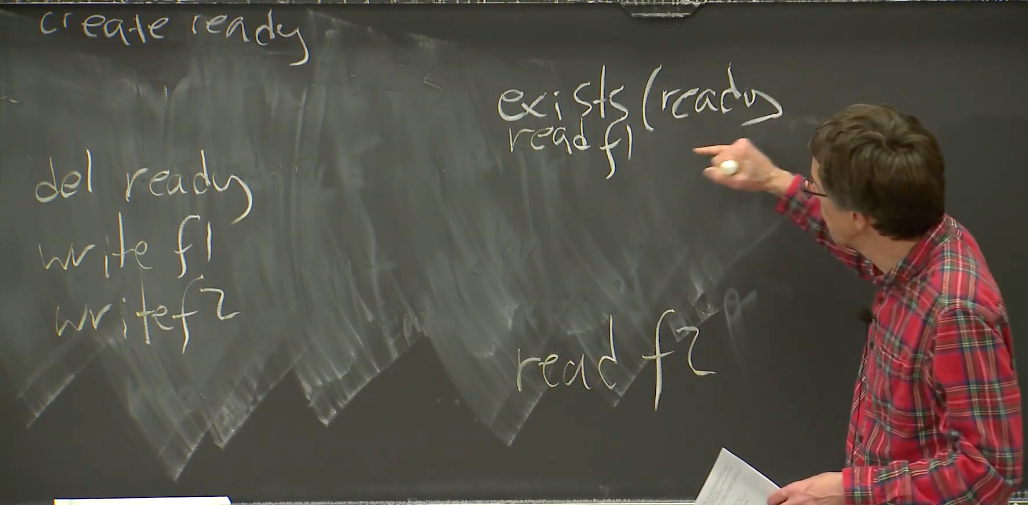
- 建立一个针对这个Ready file的watch。Ready file变了, 会通知客户端, 这样客户端就知道了, 就会重新读有没有Ready file.

- zookeeper还有一些没有解决的问题, 比如记录客户端访问次数. 如果有多个客户访问, 应该怎么记录?
- 如果是get value, 然后put value+1, 是不行的, 2个用户同时得到10, 然后放回11, 那么就是11, 不是期望的12
- 还有一个办法, get value and version, 放回version和value+1. 这样可以解决记录重复的问题, 但这样太慢了, 10个用户, 只有一个会成功放回, 这就是没有transaction的缺点, 所以有一个mini-transaction解决这个事情 -就是用watch, 下图中表示的, 这种方法也叫non-scalable lock
- 终究解决办法, 一个重要的东西, 可扩展锁
|
|
- 最大的改变就是解决了n方的时间复杂度, 这个可能是n时间复杂度,
- 如果没有比自己小的文件就获得锁,
- 监视的是自己低一个等级的文件, 在第5行中, 所以需要回到list(f*)
我们为什么这么重点讨论锁, 就是在分布式系统中, 最需要解决的文件就是两个, 一个是任务的分发和任务的执行, 任务的分发的锁比较好解决, 执行的话, 怎么检测worker有没有坏, 就是一个问题, 所以zookeeper的可拓展锁, 可以检测上一个worker的任务干的怎么样了, 是干完了, 还是中途就停下了, 停下了, 就需要数据的重组与重建. 这就是scalable lock的意义
CRAQ
链式结构
- 无故障情况很简单从第一个到最后一个, 最后一个返回.
- 有故障
- 头故障
- 消息还没到头就故障了
- 那么客户也不会收到尾部的消息
- 消息过头了
- 那么继续传递就可以了
- 消息还没到头就故障了
- 尾故障
- 前一个会接管
- 中间故障
- 这是重点, 并且解决了这个, 也会解决头尾故障的怎么判断故障的问题
- 头故障
- 一个通用的做法, 就是加上一个类似raft的外部权威机构来告诉每一个节点的状态, 包括位置, 头节点是谁, 尾节点是谁. 即使权威机构认为这两个节点活着, 但实际上, 并没有, 这也是一个问题, 可能需要好好管理, 但架构还是这样的, 为了防止brain splite
亚马逊云(AWS)演进过程
- 一开始用的单机
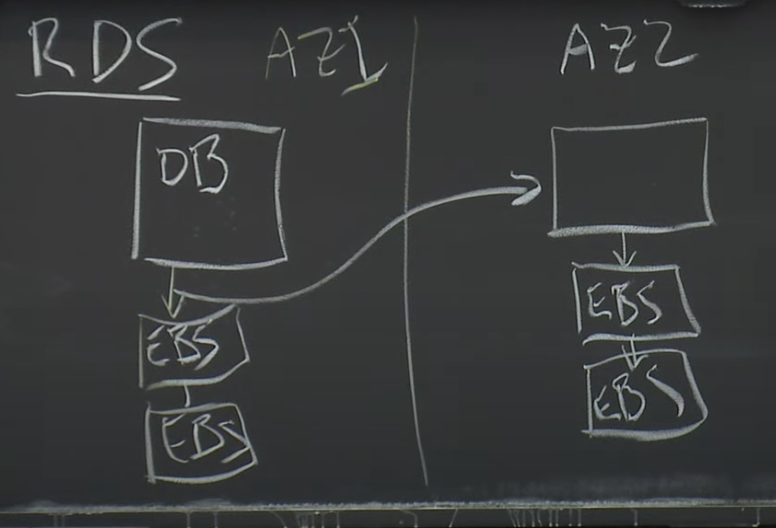
- EB2·每个服务器都安装一个数据库, 没有备份和容错, 只能快照(EB2是实例)
- EBS·有了存储卷概念, 可以链式备份, 第一个传给第二个, 第二个回复给用户, (EBS是存储卷)
- RDS·会传输数据库的一页(RDS是一项数据库服务, 是多区域的备份, 也是链式, 使用EBS)
- (Aurora)
- 传输的是log entry, 不是数据页了, 会减少很大一部分网络传输
- 然后是读写分离, 比如有n = 4个, 那么R + W ≥ n + 1, 就是有写有三个回复就可以继续了, 读有2个就可以继续了. 不管其他的, 这样可以保证速度, 宣称提高了35倍性能

事务(transaction)
会把你改之前的值, 和改之后的值, 可能是多个, 存到一个地方, 并且还有一个标识位, 用来表明是否已经完成, 没完成的话, 会根据那个地方的数据回溯.
并且每一条事务, 都有一个标号, 可以根据6个机器中的编号来判断哪些事务没在所有机器上完成. 如果有一个编号, 任何机器中都没有, 那么这个编号之后的事务都可以被丢弃了.
分页, 分片(Protection Group)
之前一直讲的是6个机器, 但这样的话, 6台机器中的其中一台机器能存的东西就是整个数据库的最大容量了, 分页可以解决这个问题.
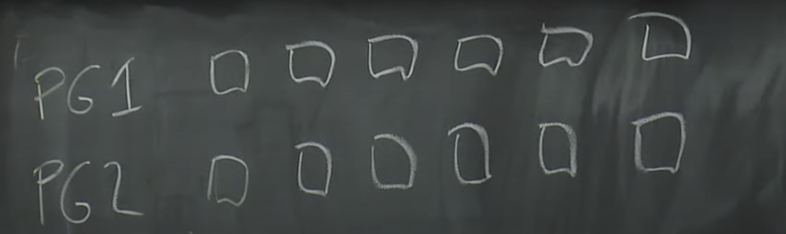
如果有存储20G内容, 一个Protection Group存储10G, 其中可能有6个机器, 然后另一个Protection Group也存储10G, 并且可能是另外6个机器, 有可能有重叠, 因为应该是随机挑选的6个. 每一个数据库的页, 可能会按照单双数存到不同的Protection Group中, 并且修改的时候会判断在哪个Protection Group中, 然后修改.
存储的时候, 放在一个Protection Group时, 要保证4+3 = 6+1就可以了.
还有就是其中一台机器里面可能属于好多个Protection Group, 恢复的话, 可以多个Protection Group里面的机器一起给这个机器数据. 这样就可以提高恢复速度了.